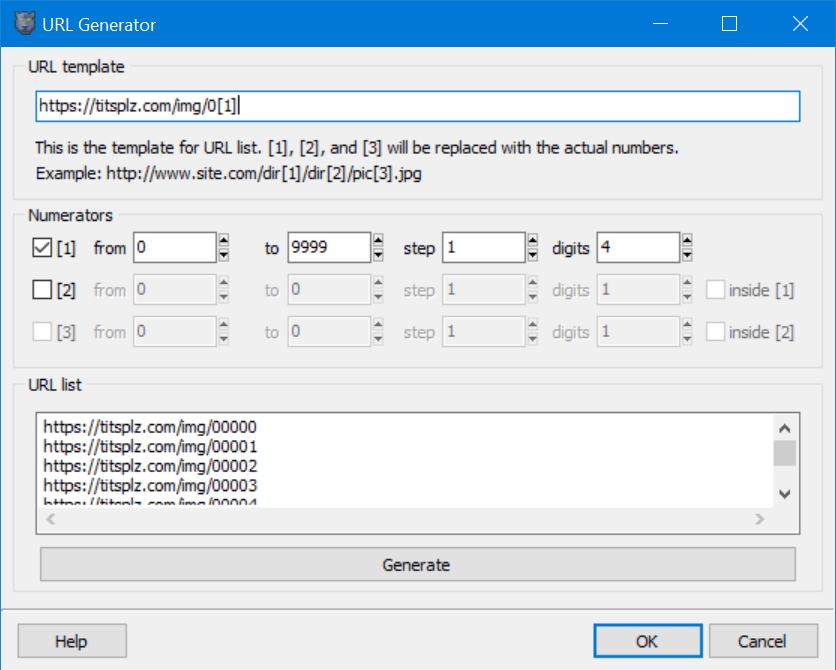
Template for titsplz.com
Posted: 26 Aug 2021, 16:58
I haven't had this program long, but I decided to see if I could learn how to make a template. It seems I happened to have a website I want to save pics from but it's quite a challenge to figure out how to make it work properly.
The website is https://titsplz.com ... but you'll notice instantly when you open it why it is so hard to rip from. They have no home page, each picture is given an id number url like so https://titsplz.com/id/[number here] ... and it seems like most pictures (but maybe not all) come from url like so https://titsplz.com/img/[same number here] ... problem is the latest post is id 131679 AND it's actually not all pictures from "titsplz.com" they actually run 5 sites in one, "Titsplz.com", "PussyPlz.com", "Wangpics.com", "YourHotPics.com", and "asstronomy.com"... which all of them are as you can tell different in subject they all use the same id numbers so assuming they started at 0 or 1 - through - 131679 is ALL these sites pictures.
The Parser I was writing was trying to just pull from Titsplz, but it seems to only get about 239 or so pictures from cutting off... I believe this has to do with how many links (or other pictures at the top of the page) load into that sliding bar. I believe the 239 cut off is however many are loaded at a time, and it loads more as you scroll.
This is about as far as I got with it, I'd love some assistance figuring out how to get it to just go down the sliding top bar grabbing those full images via the id/img system... I feel like it's possible but I'm really not sure. But since all the sites are built the same when one is figured out it shouldn't be too hard to copy over but change url for all 4 of the other mirror sites. Thanks all!
The website is https://titsplz.com ... but you'll notice instantly when you open it why it is so hard to rip from. They have no home page, each picture is given an id number url like so https://titsplz.com/id/[number here] ... and it seems like most pictures (but maybe not all) come from url like so https://titsplz.com/img/[same number here] ... problem is the latest post is id 131679 AND it's actually not all pictures from "titsplz.com" they actually run 5 sites in one, "Titsplz.com", "PussyPlz.com", "Wangpics.com", "YourHotPics.com", and "asstronomy.com"... which all of them are as you can tell different in subject they all use the same id numbers so assuming they started at 0 or 1 - through - 131679 is ALL these sites pictures.
The Parser I was writing was trying to just pull from Titsplz, but it seems to only get about 239 or so pictures from cutting off... I believe this has to do with how many links (or other pictures at the top of the page) load into that sliding bar. I believe the 239 cut off is however many are loaded at a time, and it loads more as you scroll.
This is about as far as I got with it, I'd love some assistance figuring out how to get it to just go down the sliding top bar grabbing those full images via the id/img system... I feel like it's possible but I'm really not sure. But since all the sites are built the same when one is figured out it shouldn't be too hard to copy over but change url for all 4 of the other mirror sites. Thanks all!