Page 1 of 1
Downloading non-text-file text
Posted: 08 Jul 2023, 17:35
by Glcvm
I know that this is not necessarily the focus of this software but I was curious if it was possible cause It would save me a whole lot of headache. There are a lot of websites that have captions or descriptions of Images that I would love to save for my archives. Is it possible to save parts of a sites Html with regular expressions and save it in a .txt folder in a subfolder? Or even a way to download the .htm of a page similar to how you can right click save as in a web browser. Is there a way this could be implemented in EPF?
Re: Downloading non-text-file text
Posted: 09 Jul 2023, 12:33
by Maksym
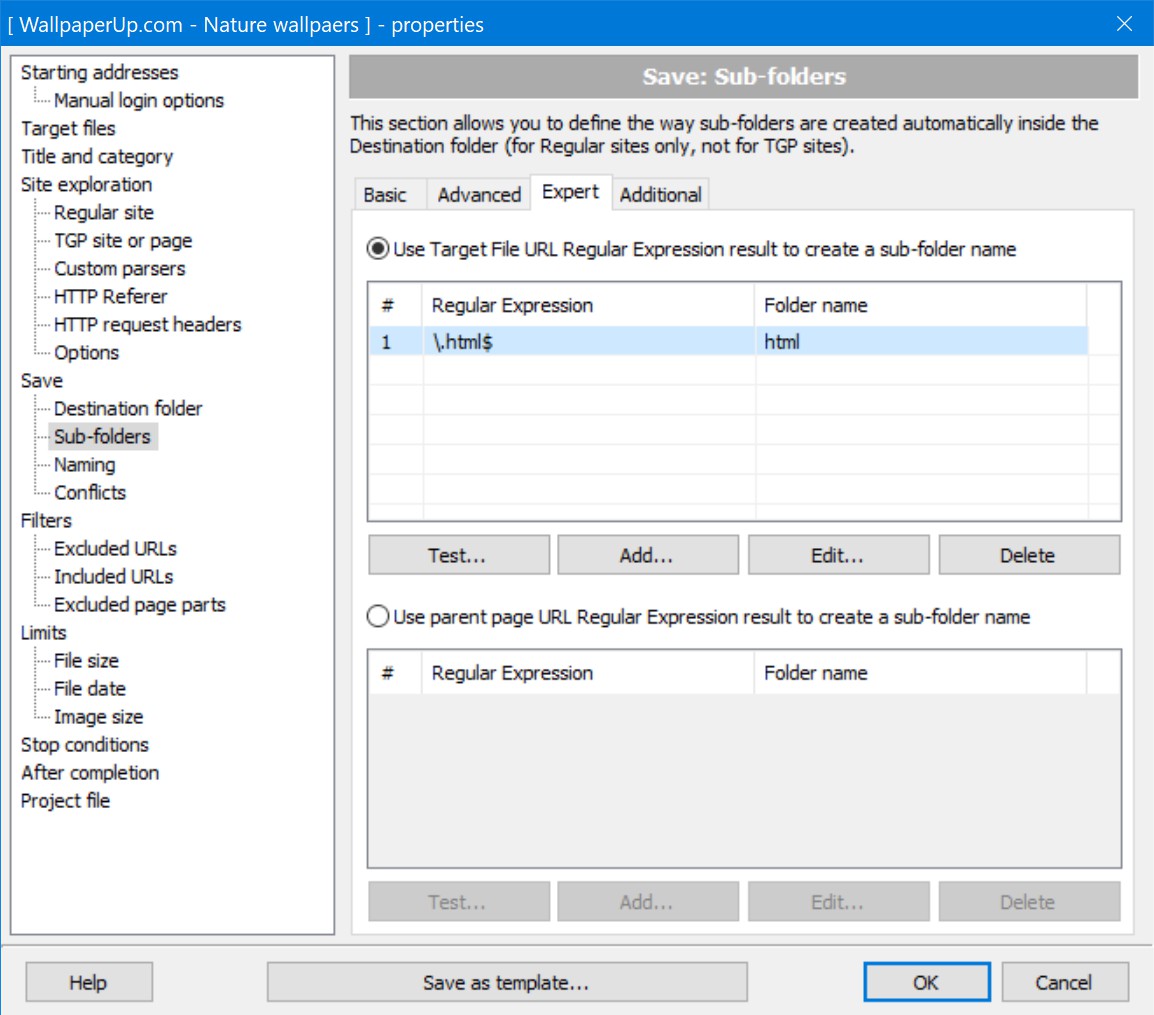
Well, the easiest way is just to add
*.html
(or whatever extension files with the descriptions have) to the Target Files. And saving them into a separate sub-folder is also quite easy (if you know how to use Regular Expressions). Here is an example:
Re: Downloading non-text-file text
Posted: 09 Jul 2023, 18:51
by Glcvm
I have tried using *.html and *.htm in the targeted files but I think it wants the site to be hosting an actual .html file or element on the webpage instead of just grabbing it like through a right click save page as. I think you misunderstood my question though, I was wondering if EPF had any way to save text content that is not part of any downloadable file. Like say for example anything within the <p> </p> within the html of a website and saved to a .txt file.
Re: Downloading non-text-file text
Posted: 10 Jul 2023, 10:30
by Maksym
No, I did understood your question. You want to save a part of a page. How do you imagine the interface for that in the program? How do you define what part of what page the program must save? And the interface must be generic, it must work for hosted .html pages, scripts, ajax requests and every other way text can be delivered via HTTP protocol. Right now there is nothing in the program that can do that. But you can save content of web pages, even if they are not .html files. If you give me example URL - I'll tell you if it's possible.
Re: Downloading non-text-file text
Posted: 16 Jul 2023, 06:44
by Glcvm
Honestly I was kind of imagining something similar to the custom parsers section of a template, but used to specify the parts of websites to save as text files rather than create urls, as for how to make that work generically I have no idea, ajax requests and stuff like that are kind of out of my depth but I'm just spitballing. What I'm trying to do is save twitter tweets and nested comments, along with the media they contain. I have tried some other programs like profile extractors and stuff like octoparse but they all seem to not quite do what I want them to. They're geared towards businesses and data collection projects with spreadsheets that make it either doesn't work, isn't viable or really hard to sort out into each tweet, I'm just trying to archive some of these profiles of inactive accounts before they get snapped by elon.
https://twitter.com/kblock43/status/1606345301542858752 I is a fine example. if I could get " What do you get when you have a 1400 hp, twin-turbo, flame-throwing V8 Hoonicorn, downtime on a film set (Gymkhana TEN) and a good friend remixing classic Christmas hits? A Hoonicorn Yule Log is what you get!! Click here:
https://youtu.be/a8A10iHf90o" into a text file along with the media that would be gold. I've been doing thousands of these, using twitter down-loaders and copy and pasting by hand for months and my hands is starting to consider separating from the rest of me.
Re: Downloading non-text-file text
Posted: 16 Jul 2023, 11:57
by Maksym
OK, I see what you need, but currently this is impossible. Extreme Picture Finder doesn't even go to the tweet pages to download the media making the download process way more faster and effective... And in general, as you already know, there is no text extractor in the program yet. And the interface for that would be even more complicated than Custom Parsers. Plus, this feature will require the program to store all downloaded pages so that the page text could be used later, after the media file is downloaded and about to be saved. And currently pages are "forgotten" right after the program parses their text. So, it looks like you'll have to make some kind of deal with your hand or hire someone to do it for you.